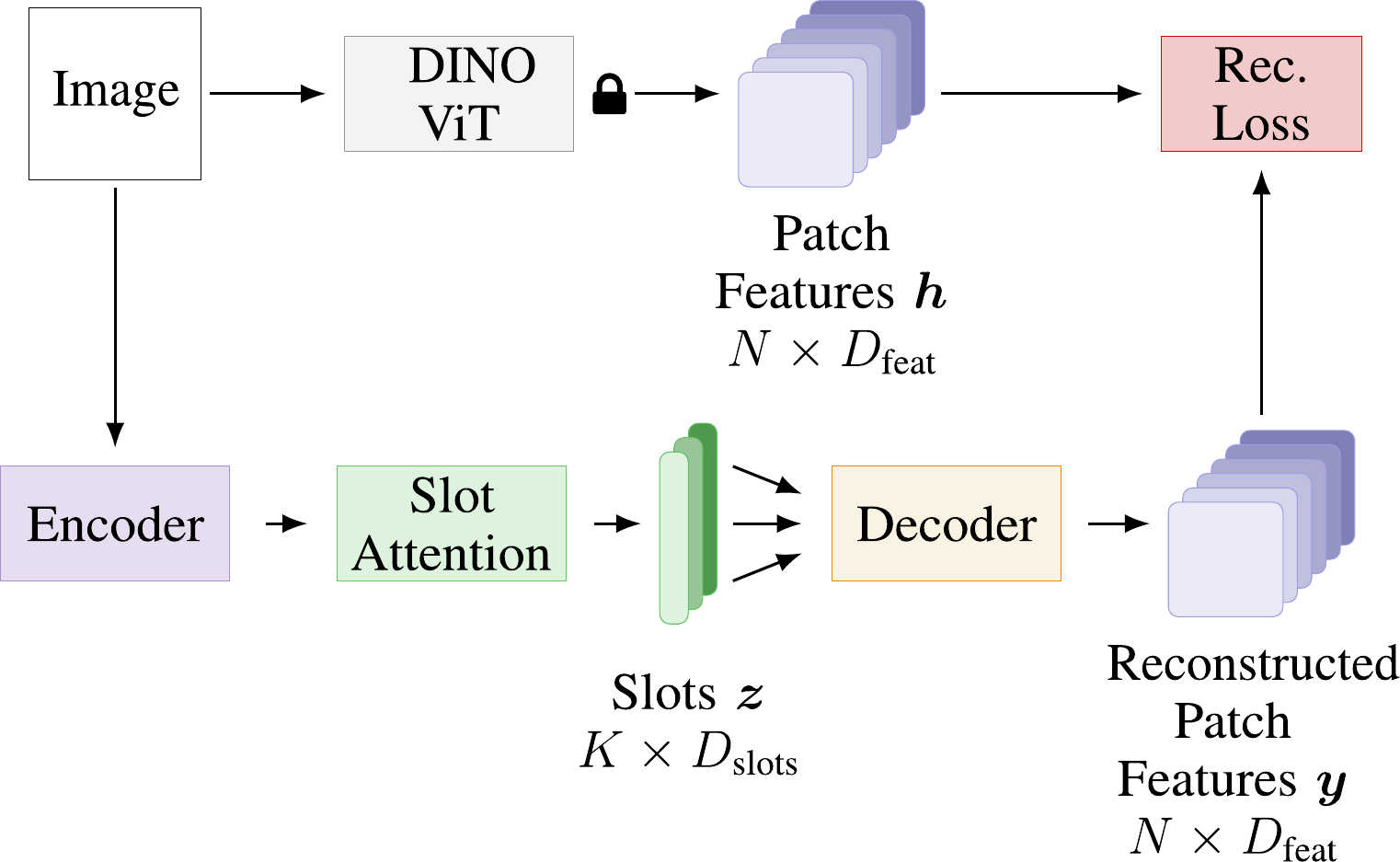
Reference Results for Object Discovery
This section is supposed to serve as a reference for the results different versions of DINOSAUR can achieve on the object discovery task.
Note that the numbers vary quite a bit depending on the encoder, the decoder, the number of slots and other hyperparameters.
In particular, the MLP decoder generally achieves higher FG-ARI than the Transformer decoder, and vice-versa with mBO.
If you reimplement DINOSAUR, your model should be able to achieve similar numbers as the ones in the table.
If you compare with DINOSAUR in your own work, make sure you either have a proper reimplementation, or simply directly use the numbers stated here.
It is generally advisable to use the strongest version of a baseline in a given reference class.
We split the results into two parts: results from the original DINOSAUR paper, and results from follow-up work, using the DINOSAUR architecture but potentially achieving stronger results.
If you would like to add your DINOSAUR-based results to this table, feel free to send us an email.
We only accept results that have a reproducible code implementation associated.
DINOSAUR Paper
| Dataset |
Encoder |
Decoder |
#Slots |
FG-ARI |
mBO |
Reference |
| MOVi-C1 |
ViT-B/16, DINO |
MLP |
11 |
66.0 |
35.0 |
Table 3 |
| MOVi-C1 |
ViT-B/16, DINO |
Transformer |
11 |
55.7 |
42.4 |
Table 3 |
| MOVi-C1 |
ViT-S/8, DINO |
MLP |
11 |
67.2 |
38.6 |
Figure 3 |
| MOVi-C1 |
ViT-B/8, DINO |
MLP |
11 |
68.6 |
39.1 |
Figure 3 |
| MOVi-E1 |
ViT-S/8, DINO |
MLP |
11 |
76.7 |
29.7 |
Table 13 |
| MOVi-E1 |
ViT-S/8, DINO |
MLP |
24 |
64.7 |
34.1 |
Figure 3 |
| MOVi-E1 |
ViT-B/8, DINO |
MLP |
11 |
79.3 |
32.7 |
Table 13 |
| MOVi-E1 |
ViT-B/8, DINO |
MLP |
24 |
65.1 |
35.5 |
Figure 3 |
| COCO2 |
ViT-S/16, DINO |
Transformer |
7 |
36.9 |
29.7 |
Table 11 |
| COCO2 |
ViT-B/16, DINO |
MLP |
7 |
40.5 |
27.7 |
Table 12 |
| COCO2 |
ViT-B/16, MAE |
MLP |
7 |
42.3 |
29.1 |
Table 12 |
| COCO2 |
ViT-B/16, DINO |
Transformer |
7 |
34.1 |
31.6 |
Figure 5 |
| COCO2 |
ViT-S/8, DINO |
Transformer |
7 |
34.3 |
32.3 |
Table 11 |
| PASCAL 20122 |
ViT-B/16, DINO |
MLP |
6 |
24.6 |
39.5 |
Table 3 |
| PASCAL 20122 |
ViT-B/16, DINO |
Transformer |
6 |
24.8 |
44.0 |
Figure 5 |
Follow-up Work
| Dataset |
Encoder |
Decoder |
#Slots |
FG-ARI |
mBO |
Reference |
| COCO3 |
ViT-B/14, DINOv2 |
MLP |
7 |
45.6 |
29.6 |
VideoSAUR code release |
1: 128x128 mask resolution
2: 320x320 mask resolution, central crops
3: 224x224 mask resolution, central crops